How I Built a Phishing Detector I Actually Trust (Multi-Model, Privacy-First, Battle-Tested)
I get a lot of email—grad school, NRC work, side projects—and every week there’s at least one message that looks legit but smells wrong. I wanted a detector that feels like my own instincts, just sharper and faster. So I built one: a production-ready, multi-model system that runs locally or in the cloud, explains itself, and doesn’t break when real-world email gets messy.
TL;DR
- Ensemble > single model. I combine a fine-tuned RoBERTa, GPT-class LLMs (OpenAI/Claude), and local LLMs (via Ollama) to catch different attack styles.
- Privacy options by design. Local-only mode so sensitive emails never leave my infrastructure; cloud mode for heavier reasoning when I allow it.
- Productionized. Flask API, Dockerized, Nginx + SSL, deployed on a Hetzner VPS (custom domain), with monitoring and graceful fallbacks.
- Transparent decisions. Verbose mode shows each model’s vote + rationale so I can debug false positives quickly.
- Roadmap. Browser extension, richer HTML/metadata analysis, federated learning, and graph-level campaign detection.
Why I cared enough to build this
- My inbox is mission-critical. I’m juggling a Master’s at uOttawa and part-time engineering at the National Research Council. Missing an email from a supervisor is bad; trusting a fake “invoice due” is worse.
- I’m privacy-obsessed. I’ve shipped other privacy-first tools (e.g., local finance dashboards), and I want the same control for email security: on-device or self-hosted first, cloud only when I opt in.
- I like systems that explain themselves. Debugging hazy “blocked for safety” messages is painful. I want to know why an email got flagged.
Design principles (the guardrails I kept)
- Model-agnostic: Hot-swap models (local/cloud) without rewiring the app.
- Production-first: Clean startup, fast first inference, retries/backs-offs for flaky APIs.
- Extensible: New models and preprocessing steps drop in with minimal friction.
- Explainable by default: Per-model outputs, confidence, and short rationales.
The system at a glance
-
Preprocessing Engine: Minimal but surgical cleanup—strip/normalize URLs and special characters while preserving the “tells” (punctuation, layout hints, phrasing).
-
Model Orchestrator: Routes requests (local vs cloud; speed vs accuracy), runs models in parallel, aggregates votes intelligently.
-
Core Models:
- RoBERTa (fine-tuned): Fast, pattern-sharp, offline.
- OpenAI GPT-class: Contextual/social-engineering reasoning.
- Claude: Great at subtle persuasion cues and edge cases.
- Local LLMs (Ollama): Private, customizable, org-specific.
- Custom transformers: For my own corpus/attack patterns.
-
API Server: Flask routes, standard JSON responses, consistent error handling.
-
Infra: Docker images, Nginx reverse proxy with SSL, Hetzner VPS, domain configured, caching + graceful degradation.
-
Monitoring: Latency/error-rate focus; model-health probes; alerts when cloud providers hiccup.
Why an ensemble (and how the votes work)
Different attacks stress different muscles:
- RoBERTa nails phrasing quirks and templated lures.
- LLMs reason about context: “Why would payroll email me from this domain?”
- Local models preserve privacy and can be tuned to my org’s email style.
I aggregate with weighted voting + confidence gates. Disagreement is a feature: when models split, I inspect those emails—they’re often the interesting edge cases.
What surprised me (building from lab to prod)
- The preprocessing paradox. Over-sanitize and you erase the very fingerprints (spacing, punctuation, odd phrasing) that give phish away; under-sanitize and HTML noise derails tokenizers. The sweet spot took A/B tests on real corpora.
- Startup choreography matters. Preloading models vs lazy loading changed first-request latency from ~10–15s to sub-second. Orchestrating five models without RAM spikes required careful sequencing.
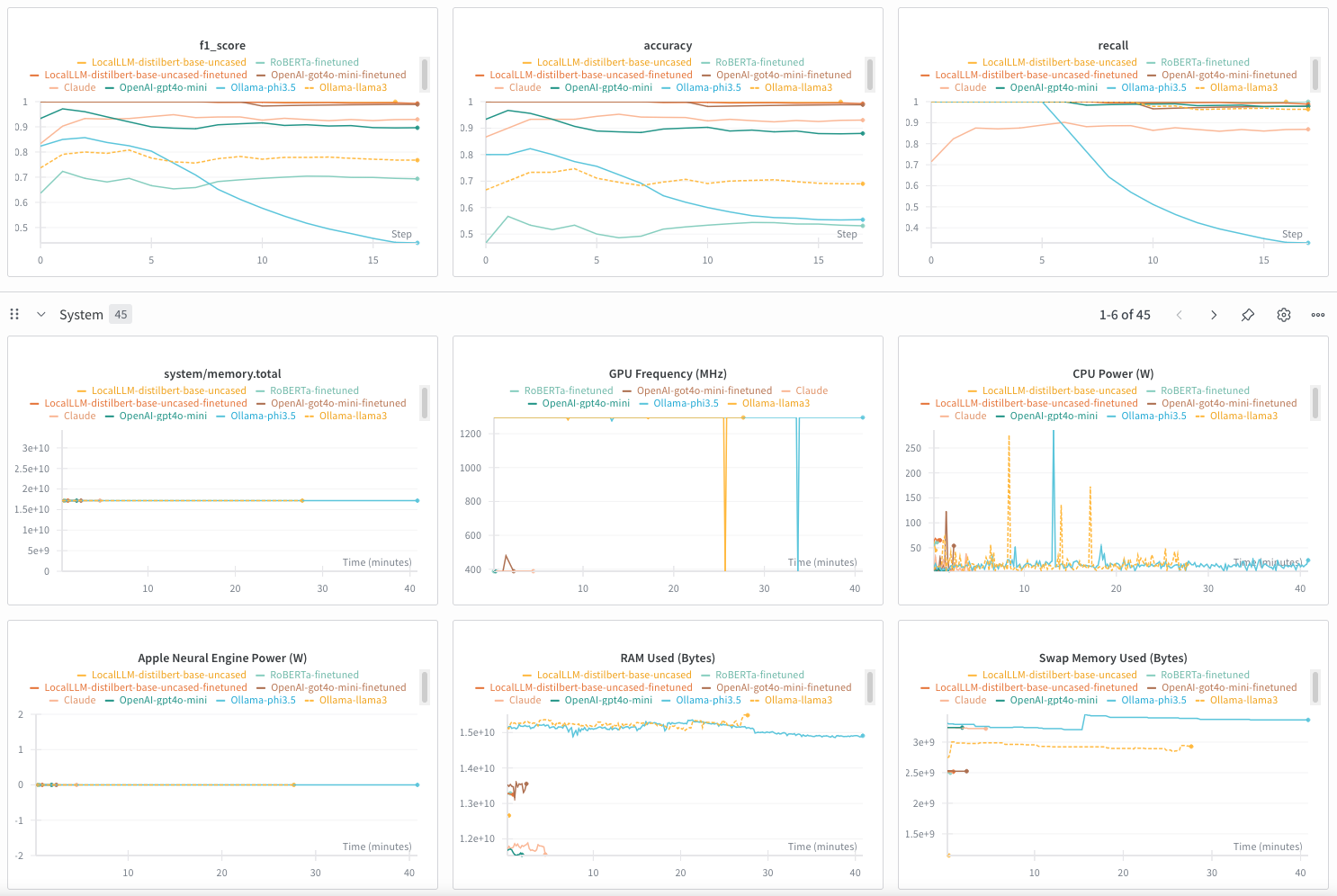
- Metrics reality check. Academic F1 on clean datasets ≠ field performance. Real mail is multilingual, messy, and evolving; I track precision aggressively because false positives are costly.
- Provider hiccups happen. OpenAI/Anthropic are quick—until they aren’t. Retries, timeouts, and local fallbacks are non-negotiable.
Training notes (the RoBERTa story)
- Data quality beats volume. ~10k curated, well-labeled examples outperformed a noisy 100k dump.
- Regularization + augmentation prevented template memorization.
- Longer context windows helped with thread-based attacks where a legitimate thread gets hijacked later.
Deployment & ops
- Stack: Flask + Docker (multi-stage builds), Nginx (SSL/headers), Hetzner VPS, domain configured, CI for image builds.
- Performance: Preloading critical models; async calls for cloud LLMs; caching frequent provider responses.
- Resilience: Clear fallbacks (cloud → local), uniform error payloads, circuit-breakers on provider timeouts.
- Dev-prod parity: Same images everywhere; config via env vars; reproducible runs.
What I learned
- Production ML = systems engineering. The “model” part is half the work; the other half is startup, memory, latency, retries, and observability.
- Explainability buys trust. A quick rationale (“sender domain mismatch + urgent payment language”) turns a black box into a tool I can actually use.
- Continuous adaptation is table stakes. Attackers evolve; so must the detector. Monitoring drift matters more than a heroic single-point F1.
Roadmap ? (near → far)
- Near: Gmail/Outlook extension with inline warnings; HTML/attachments parsing; sender-auth signals (SPF/DKIM/DMARC); model-drift alerts.
- Next: Federated learning so orgs can improve models without sharing raw mail; smarter ensemble weights based on scenario.
- Later: Graph-level analysis (campaign clustering across senders/domains), behavioral signals for account compromise.
A personal note
I built this partly because I’m the friend people forward suspicious emails to (“Youssef, is this real?”). Now I have a tool that reflects how I think—privacy-first, explainable, and fast—and that I’m comfortable recommending to my lab mates and colleagues. It’s not “set and forget”; it’s a living system that learns with me.