chessLLM: Building a Chess Arena for LLM Evaluation
Can Claude beat GPT-4 at chess? Does Gemini play principled openings, or is it just producing plausible-looking moves until the position collapses?
I kept seeing those questions answered through scattered anecdotes, so I built chessLLM: a terminal-first Python arena where language models play real chess against each other, against Stockfish, and against a random baseline. It validates every move, logs complete games, tracks cost and latency, and gives me a repeatable way to compare models on a bounded reasoning task.
The spirit is similar to my LedgerGlass project: keep the interface small, make the system observable, and do not let hidden costs sneak up on you. The difference is that this time the interface is a terminal chessboard, and watching two models argue with the position starts to feel less like a benchmark and more like a very strange sport.
TL;DR
- What it is: A Python CLI for head-to-head LLM chess, with strict move validation, PGN logging, live dashboards, and smart opponent matching.
- Who can play: OpenAI, Anthropic, Google, Stockfish at configurable difficulty, and a random baseline for sanity checks.
- Two modes: Direct prompting, or an agent-assisted mode that gives the model a lightweight analysis toolkit before it chooses a move.
- Why I built it: I wanted more than "this model feels smarter." Chess gives me legal moves, wins and losses, clock time, illegal-move rates, costs, and complete replayable traces.
- What is next: Opening books, tournament brackets, MCTS-style planning, and experiments with multi-agent collaboration.
Why chess, why now
I am a grad student at uOttawa and a part-time software engineer at Canada's NRC, so my day-to-day lives somewhere between research habits and shipping constraints. I like projects that are rigorous enough to teach me something, but small enough that I can actually finish the first useful version.
Chess fit that shape well.
It is bounded, public, and unforgiving. A model cannot hide behind eloquent prose if it hangs a queen. It either returns a legal move or it does not. It either survives a tactic or it misses it. That makes chess a useful pressure test for the kind of structured reasoning people often claim LLMs have.
I also wanted to study agent behavior without building a giant open-ended system. "Can a model choose a better chess move if it first evaluates material, king safety, development, threats, and candidate moves?" is much easier to measure than "can an agent do everything?" The scope stays honest.
The last reason is practical: running model-versus-model games can get expensive. I wanted cost tracking to be part of the core loop from day one, not an afterthought in a spreadsheet later.
The constraints I kept
These constraints kept the project from sprawling:
- Terminal-first: Unicode pieces, board coordinates, last-move highlights, live updates, and keyboard shortcuts. No browser required.
- Provider-agnostic: One interface for OpenAI, Anthropic, Google, Stockfish, and simple baselines.
- Cost-aware: Per-game, per-move, and per-provider spend tracking, with budget limits and automatic stops.
- Strict about legality: Every move is parsed, validated, and either applied or rejected. Stockfish helps keep the game honest.
- Replayable: Games are saved as PGNs with metadata, so results can be shared, inspected, or rerun.
- Simple to iterate on: The CLI should stay fast enough that testing a new prompt, model, or agent strategy feels cheap.
How the system works
At the center is a game manager that owns the board state, orchestrates turns, talks to model clients, validates moves, updates the live UI, and writes the result to storage.
The main pieces are:
- Core models:
BotSpec,GameRecord,LadderStats, andLiveStatekeep configuration, history, ranking, and dashboard state explicit. - Engine layer: Stockfish handles legal move checking and can also play as an opponent at calibrated ELO levels.
- LLM layer: Unified clients wrap OpenAI, Anthropic, and Google so changing providers does not change the game loop.
- Game manager: Runs turns, handles timeouts and retries, logs PGNs, tracks timing, and records token/cost usage.
- Agent system: Adds an optional reasoning pass before move selection.
- Storage: SQLite keeps historical games, leaderboards, timing data, and spend analytics.
The basic loop is intentionally boring:
- Convert the current position to FEN.
- Ask the active player for a move in UCI format.
- Parse the response.
- Validate the move.
- Apply it, log it, update stats, and repeat.
That boring loop matters. Once it is reliable, the interesting part becomes comparing behavior rather than debugging broken plumbing.
Standard prompting vs. agent mode
The default mode is deliberately minimal. The model receives the position, a strict output format, and enough context to return one legal UCI move. If it returns invalid notation or an illegal move, the game manager catches it and can retry or record the failure.
Agent mode, enabled with --use-agent, adds a lightweight analysis step before the final move choice. The model evaluates the position through a structured checklist:
- Position quality: center control, piece activity, king safety, pawn structure, and development
- Material: standard piece values, imbalances, and trades
- Move type: captures, checks, castling, development moves, tactical ideas, and defensive moves
- Endgames: king activity, pawn races, passed pawns, and coordination
- Threats: basic tactical detection and defensive urgency
It then scores legal candidate moves, adjusts for game phase, chooses a move, and returns a confidence score with a reasoning trace.
The difference is noticeable. Raw prompts can look fine in calm positions, but they break down quickly when the board gets tactical or the notation context gets long. Agent mode is not magic, but it makes the model more consistent. It catches obvious blunders more often, produces cleaner move choices, and gives me a trace I can inspect when something goes wrong.
The terminal UI
I did not want a wall of logs. I wanted a small application that happened to live in the terminal.
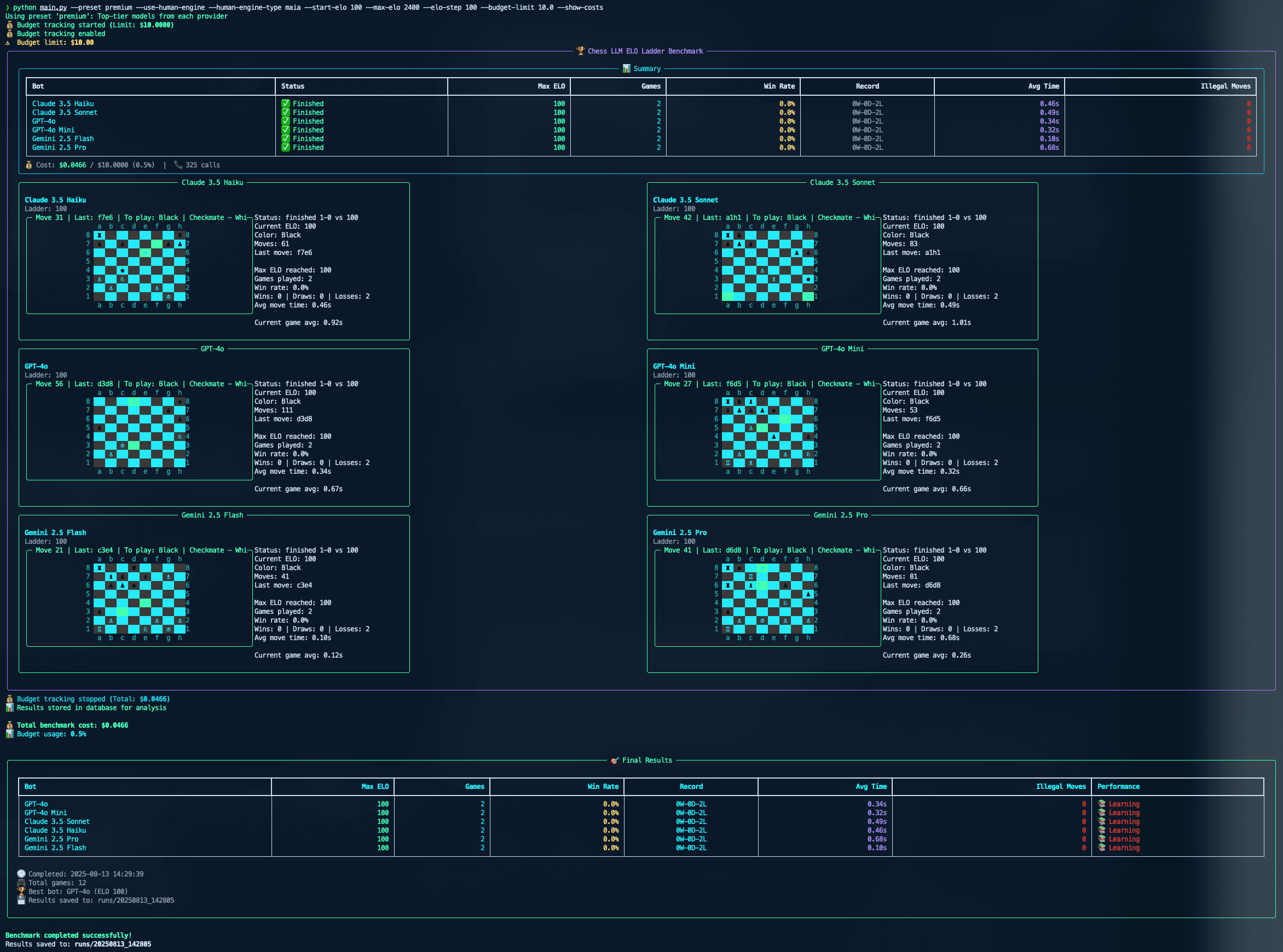
The UI uses rich to render a board with Unicode pieces, coordinates, and last-move highlights. Around the board, it shows live ELO estimates, win rates, move timers, provider names, token usage, and running costs. Opponent selection supports random pairings, specific model matchups, Stockfish at a chosen ELO, and ladder-style climbing.
This was one of the most satisfying parts of the project. Most of my recent work has been web apps and APIs, so returning to a tight CLI felt refreshing. Run a command, watch the board update, see two AIs fight for the center, and immediately know what the system is spending.
No routing. No CSS breakpoints. Just game state, async calls, rendering, and logs.
What held up well
AsyncIO stayed readable. The game loop can wait on providers, refresh the dashboard, handle timeouts, and recover from bad moves without turning into a knot.
The terminal can feel polished. rich makes a real difference. A good terminal UI is not just "logs with color"; it can feel like an actual control surface.
Small prompt changes matter. Output formatting, move history length, and how candidate moves are presented all have visible effects on parsing stability and move quality.
Engines keep the evaluation grounded. Stockfish gives me legality, calibrated difficulty, and a strong reference point. It also prevents the benchmark from becoming two models confidently agreeing on nonsense.
Cost tracking changes behavior. Seeing spend per move and per game makes it easier to decide which experiments are worth running. It also makes model comparisons more honest: a stronger result matters differently if it costs ten times as much to produce.
What surprised me
The biggest surprise was how quickly LLM chess behavior becomes legible. You can see a model that understands opening principles but loses track of pinned pieces. You can see another model obey notation perfectly but choose passive moves. You can see long games stress context management in a way short puzzles do not.
The second surprise was how useful the agent trace became for debugging. When a model blunders in standard mode, I often only know the output was bad. In agent mode, I can see whether the failure came from missing a threat, overvaluing material, ignoring king safety, or choosing from a weak candidate set.
That matters because I am not just interested in who wins. I am interested in how the system fails.
Analytics and replayability
Every game produces artifacts I can inspect later:
- PGN logs with model names, configuration, timing, and result metadata
- Historical leaderboards with ELO deltas
- Per-move latency and token usage
- Per-provider cost reports
- Game records stored in SQLite for later analysis
That makes chessLLM feel less like a demo and more like an evaluation harness. A single game can be entertaining, but the real value is watching patterns appear across many games: illegal move rates, collapse points, cost-per-win, response-time variance, and how much agent mode helps different providers.
What I would improve next
The current version is useful, but there are obvious next steps:
- Opening books so early-game quality is not dominated by prompt luck.
- Tournament brackets for repeatable model pools and cleaner comparisons.
- MCTS-style planning to test whether shallow search helps models avoid tactical traps.
- Multi-agent collaboration where one agent proposes candidate moves, another critiques them, and a final agent chooses.
- More evaluation views for illegal moves, blunder rates, cost-per-game, and phase-specific performance.
I am also curious about using Stockfish not just as an opponent, but as a post-game reviewer: where did the model first lose the thread, and did the agent trace show warning signs before the blunder?
Closing thought
chessLLM started as a simple question: "Which LLM plays better chess?" The more interesting question became: "What kind of scaffolding helps a model reason more reliably under rules?"
That is the part I want to keep exploring. Not agents as a vague promise, but agents as small, observable systems with clear constraints, measurable outputs, and enough instrumentation that failure becomes useful.